Developing A Data Science Strategy
Developing a data science strategy within an organization of any size can be a major challenge. Executing on a strategy can be even more difficult, especially in larger organizations. However, if done well, a properly developed data science capability and executed strategy can materially impact an organization's ability to compete in terms of both growth and process optimization. In this post, I will present an approach to developing a data science strategy. But before diving into strategy development, I will spend time defining data science and the fundamental capabilities and work processes an organization needs to do it effectively.
Data Science Defined
Wikipedia defines data science as "a multi-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data." Note that this definition does not focus on data set size, technology, or specific tools or types of algorithms. Instead, it emphasizes using science and structured processes to generate knowledge.
Data Science Fundamentals
Now that a definition of data science has been established, we can discuss what fundamental building blocks are needed to build a data science capability and apply it effectively. There are three building blocks that any organization can invest in to construct a data science capability. An organization can be strategic in developing their data science capability by making conditional investments in these fundamentals based on competitive context, operating constraints and time horizon.
Skills
As the definition implies, data science skills are drawn from a variety of fields, including mathematics and computer science, as well as domain knowledge of a particular industry or business. Larger data science teams will also require skills in management and leadership to support scaling.
Technology
Technology enables the collection, storage, and organization of data as well as data analysis, machine learning, and dissemination and integration of information. As mentioned earlier, depending on context and constraints, the technology could be as simple as spreadsheet software or as complex as a big data, real-time cloud computing environment.
Data
Of course, no data science capabiity can exist without meaningful data. It is critical to acquire data containing information that sufficiently characterizes the dynamics and structure of the marketplace and its actors, including customers, employees, and the processes they execute to do business and make decisions.
High Level Goals
High level data science goals fall into two categories: the creation and acquisition of strategic knowledge and moving an organization from its current state towards an automated, adaptive decisioning state.
Automated, Adaptive Decision Making
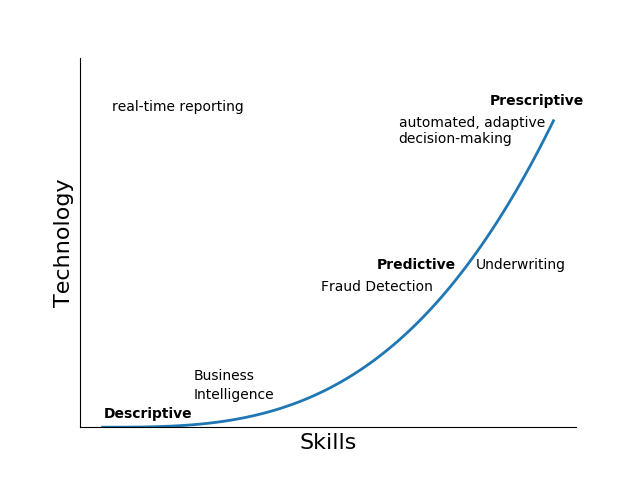
Figure 1: Organizational Decisioning State Space
Using these building blocks, a data science capability can be constructed by thinking about current strengths and weaknesses within an organization and how they map onto the space shown in Figure 1. The figure shows how investments in technology and skills enable use cases of increasing complexity. For example, small investments in both skills and technology are required to create a descriptive capability, which enables business intelligence and reporting. Significant investments in technology and skills enable robust automation of complex business processes. Data investments must precede investments in skills and technology represented in the Figure 1.
An effective data science strategy will transition an organization through this space by efficiently and iteratively investing in the fundamentals and then applying the data science capability to use cases that move it towards the prescriptive sub-space and as a result, evolve the organization into one with an automated, adaptive, decisioning engine.
Strategic Knowledge Acquistion and Generation
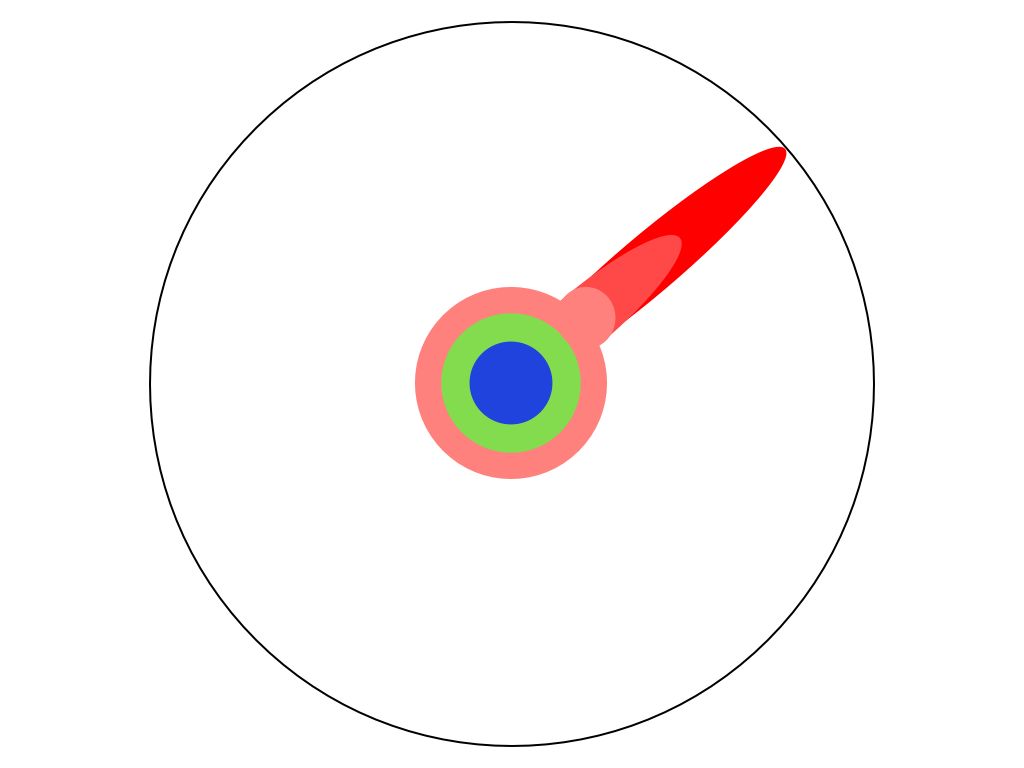
Figure 2: Business or industry knowledge universe is represented by the circle. The colored areas represent acquired knowledge. Knowledge most common is closest to the center of the circle while scarcer and newer information is closer to the edge.
Another goal that an organization should strive to achieve is the strategic acquisition and generation of knowledge. Strategic knowledge enables the effective and efficient application of data science to business problems that produce meaningful differentiation in the market.
Matt Might's blog article and corresponding set of figures do a terrific job of explaining this type of goal through the lens of earning a Ph.D. Figure 2, was taken from his great article.
Data Science Development Lifecycle
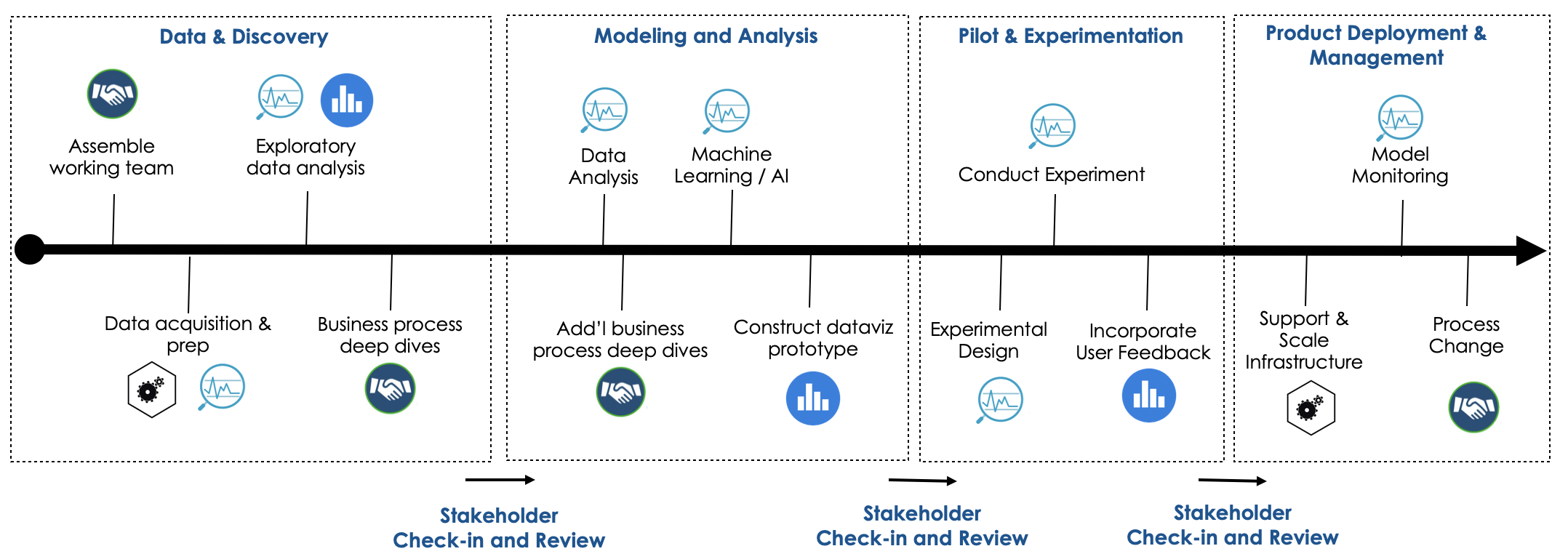
Figure 3: Data Science Development Lifecycle
Now that we have high level goals and a framework for guiding our investment in fundamentals to evolve an organization into an automated, adaptive decision making engine, we can turn our attention to a generalized work process that can be used for execution in any organization.
Before moving into a detailed explanation of the process, it is worth mentioning that successful execution generally requires a partership with a senior stakeholder who is accountable for capturing value from the process outcome.
Data and Discovery
The data and discovery phase of the lifecycle focuses on three objectives:
- Defining a problem to be solved or a question to be answered
- Defining and understanding the business process
- Acquiring and understanding the data that represents the business process
Once these objectives have been completed, a stakeholder check-in should be performed. During this check-in, the results of the data discovery and business process review should be presented. Using these results, a collective decision should be made to either stop the project or continue to the next phase.
Modeling and Analysis
In the modeling and analysis phase, the problem or question is solved or answered using historical data and a rigorous data analysis. This almost always produces three key outputs:
- The creation of a statistical model
- A prototype that uses the statistical model to capitalize on the answer to the question or solution to the problem
- An estimate of the prototype's value.
Experimentation
If the findings presented in the prior phase are valuable enough to warrant a change in operations, a formal experiment or pilot is conducted to ensure the results obtained using the historical data are obtainable in the present. This is a crucial step in the lifecycle, because it where the project is first exposed to change management. It is during this phase that a process is completely automated or people start changing what they do on a day to day basis, albeit on a controlled basis. If appropriate steps have been taken early on in the project, then the change management required to execute the experiment should be expected by the organization.
Production Deployment
Finally, if the results of the pilot or experiment are meaningful enough to warrant a large scale change, then the business process adjustment as well as the prototype and statistical model created and tested, are moved into production and integrated with necessary business applications. System and model monitoring are put into place to track data and system performance through time. Business process monitoring is also enhanced to ensure that metrics and decisions are recorded and tracked through time.
Strategy Development
Thus far we have discussed how to develop a data science capability by investing in the fundamental buildings of skills, technology, and data. We have also reviewed how to systematically apply a data science capability to a business problem to obtain meaningful value. Now, we are ready to review an approach for identifying problems of meaningful value to the organization, integrating solutions into the business, and tracking value through time.
Choosing where to focus and apply resources can be done by following the steps.
- Define the organization's revenue, product, and customer lifecycles
- Classify each stage in each of the lifecycles as either one that could or is a source of strategic differentiation or cost savings.
- At each stage, assess the quality of the leadership, state of the technology, process and data with respect to the goals.
To ensure that deployment can be done at scale, a limited set of patterns should be defined. These patterns should ensure that data science solutions can support both decision-support and pure automation patterns. Where integration is required, systems should be assessed to ensure they can support the chosen deployment and integration strategy.
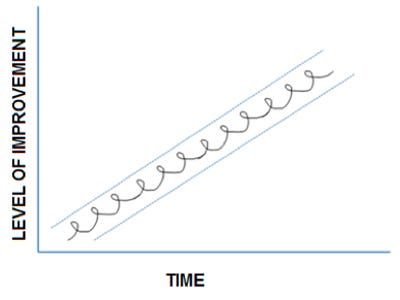
Figure 4: Ray Dalio's representation of continuous improvement to producitivity.
Tracking the impact of data science in an organization is straightforward, if the development lifecycle is followed rigorously. Since each data science project begins by specifying a problem or question that can be measured and connected to an outcome within a business process, capturing the value of process changes becomes trivial. Following a successful project, the data science system should be enhanced continuously through time, using the original metric as a measure of impact.
Closing Remarks
When planned for and implemented properly, data science projects will produce meangingful value for an organization. In particular, when either building or applying a data science capability and strategy, successful implementation will:
- Rely on a structured process focused on knowledge discovery and hypothesis testing to enable long term success or rapid, controlled failure.
- Invest early in skills and data. Both are more resilient than technology.
- Ensure that a collaborative and cross-functional approach is applied to solving and answering all business problems and questions.